【数据结构】ds笔记5-树
本篇笔记总结DSPv2b_5(树与二叉树) for student内的相关内容。更加的抽象,更多的图片……程序员上辈子是伐木工吗,这辈子种树还债。最后,本人学艺不精,只是一边看着ppt一边敲敲改改,如有疏漏,欢迎提出喵~o( =∩ω∩= )m
1 树的基本概念
1.1 树的定义
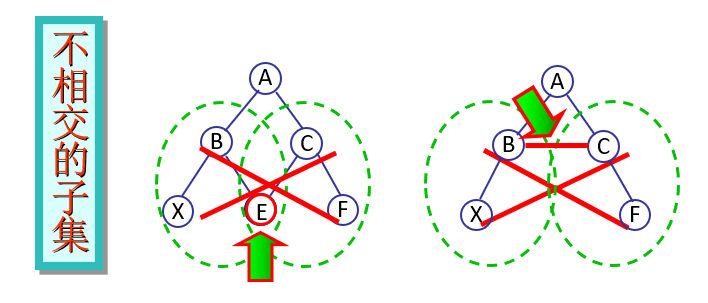
树是由n>=0个结点组成的有穷集合(不妨用符号D表示)以及结点之间关系组成的集合构成的结构,记为T。当n=0时,称T为空树。在任何一棵非空的树中,有一个特殊的结点t∈D,称之为该树的根结点;其余结点D–{t}被分割成m>0个不相交的子集D1,
D2, …
,Dm,其中,每一个子集Di分别构成一棵树,称之为t的子树。
1.2 树的特点
- 有且仅有一个结点没有前驱结点,该结点为树的根结点;
- 除了根结点外,每个结点有且仅有一个直接前驱结点;
- 包括根结点在内,每个结点可以有多个后继结点。
1.3 树的逻辑表示方式
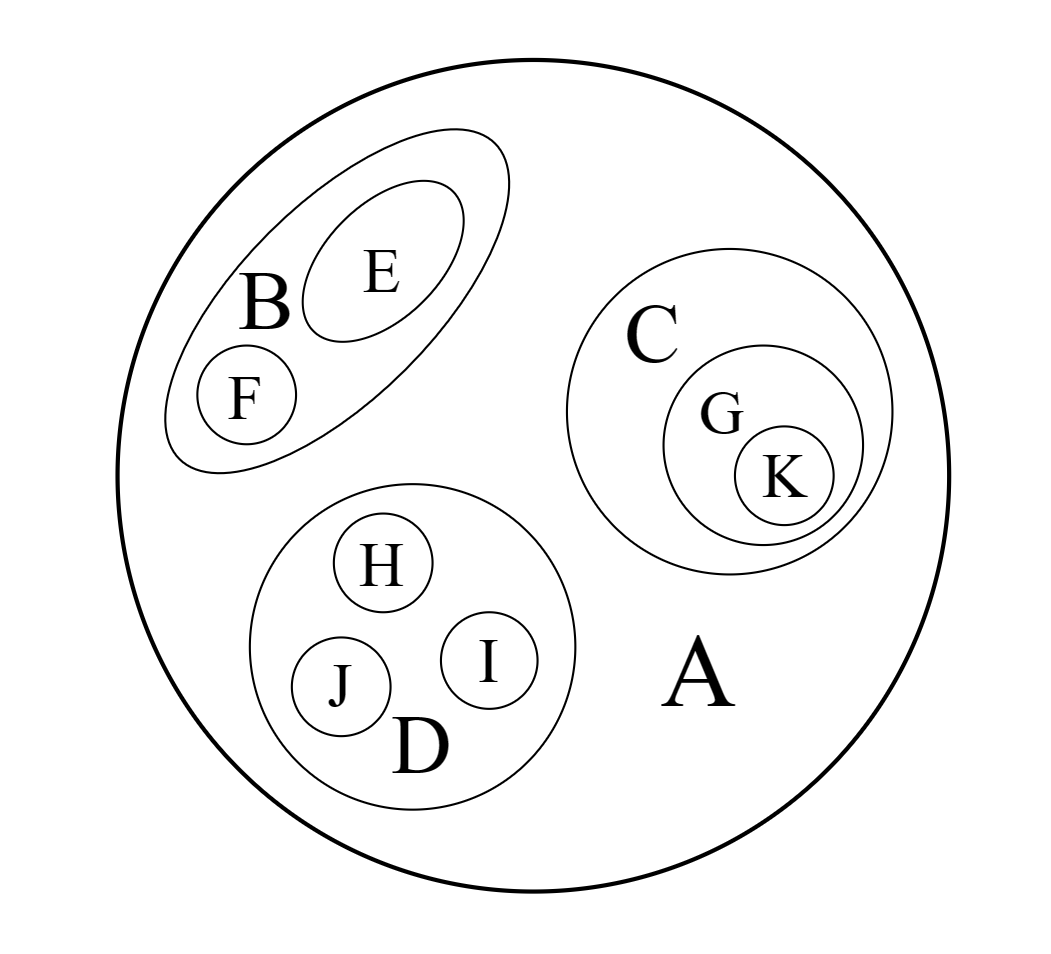
文氏图表示法
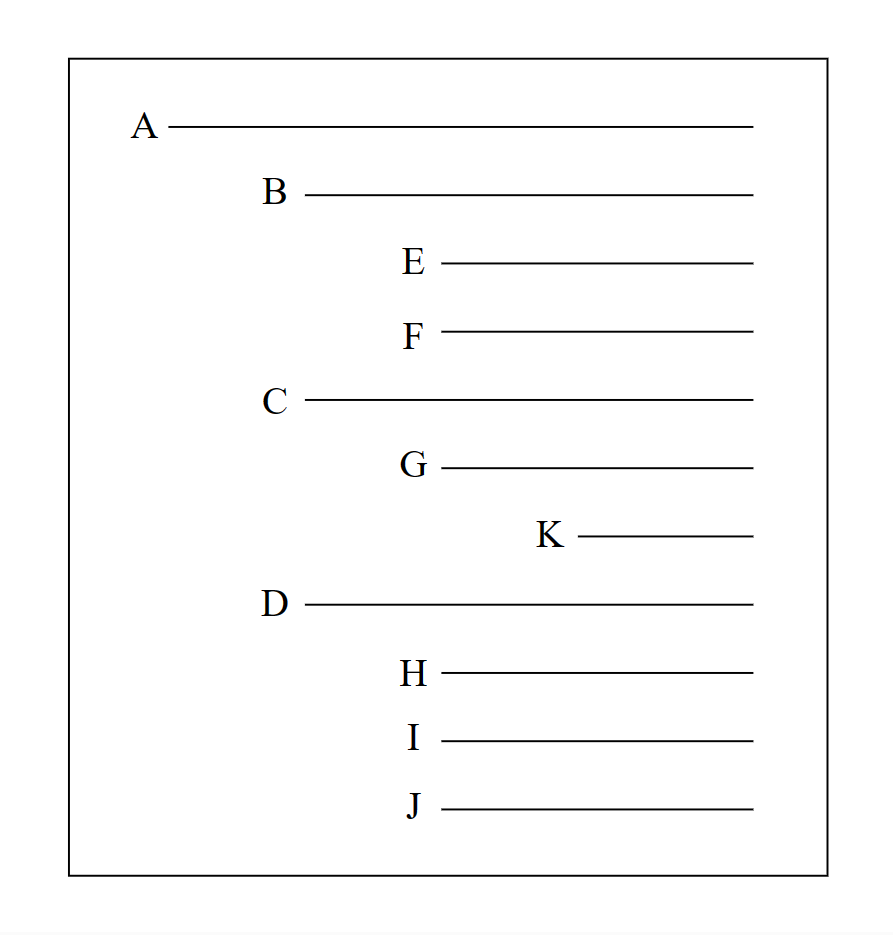
凹入表示法
嵌套括号法(广义表表示法)
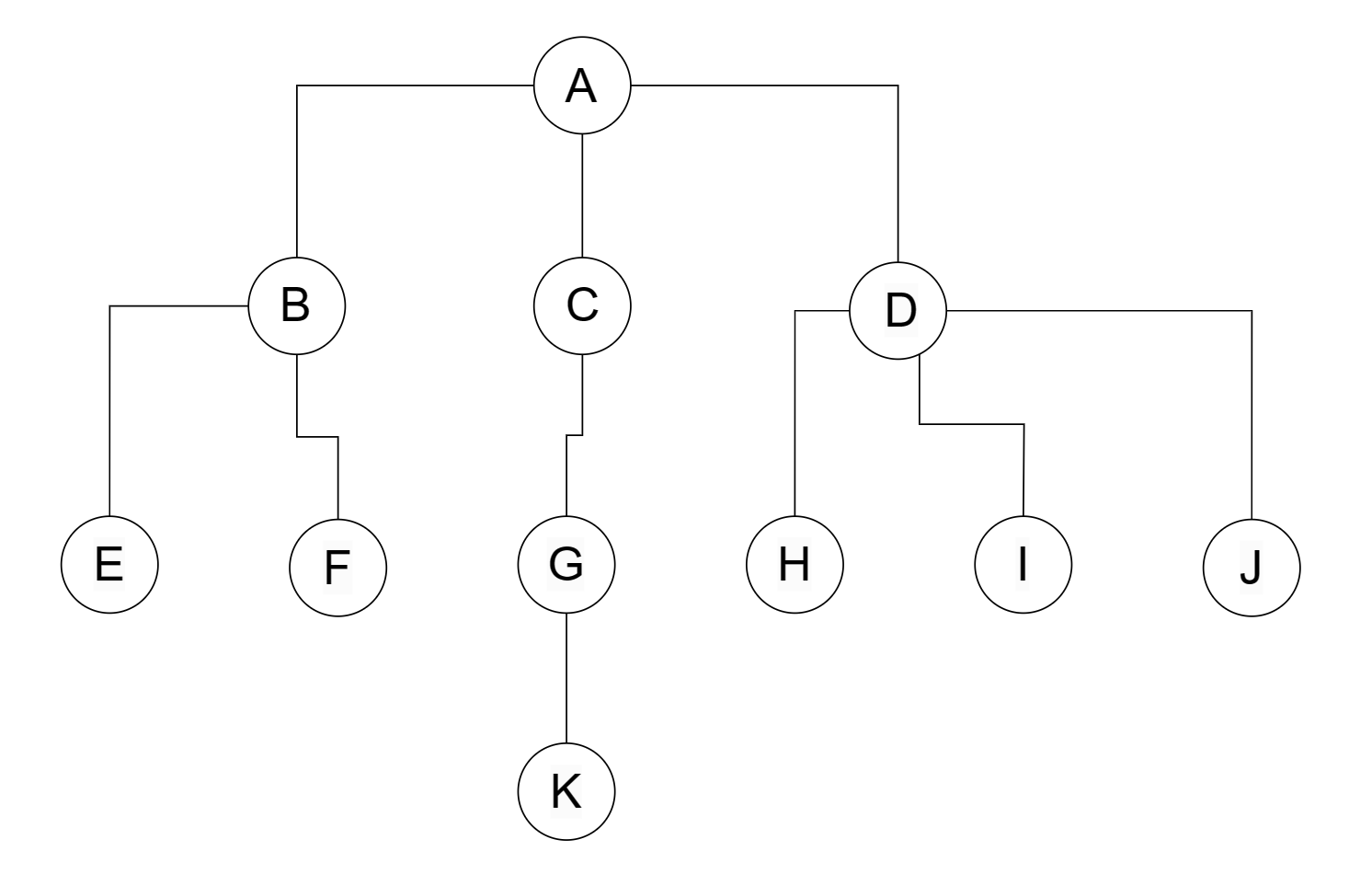
A(B(E, F), C(G(K)), D(H, I, J))
树形表示法
1.4 基本名词术语
结点的度:该结点拥有的子树的数目。
树的度:树中结点度的最大值。
叶结点(终端结点):度为0的结点。
分支结点(非终端结点):度非0的结点。
树的层次:根结点在第1层,若某结点在第i层,则其孩子结点(若存在)为第i+1层。
树的深度/高度:树中结点所处的最大层次数。
路径:对于树中任意两个结点di和dj,若在树中存在一个结点序列d1, d2, ..., di, .., dj,使得di是di+1的双亲(1<=i<j),则称该结点序列是从di到dj的一条路径。路径长度为路径结点数-1。
祖先与子孙:若树中结点d到ds存在一条路径,则称d是ds的祖先,ds和d的子孙。
从根结点到树中其余结点均分别存在一条唯一路径。
一个结点的祖先是从根结点到该结点路径上所经过的所有结点;而一个结点的子孙则是以该结点为根的子树上的所有其他结点。
树林(森林):m>=0棵不相交的树组成的树的集合。
树的有序性:若树中结点的子树的相对位置不能随意改变,则称该树为有序树,否则称该树为无序树。
2 树的存储结构
分为顺序存储结构和链式存储结构(居多)。
2.1 多重链表结构
2.1.1 定长结点的多重链表结构
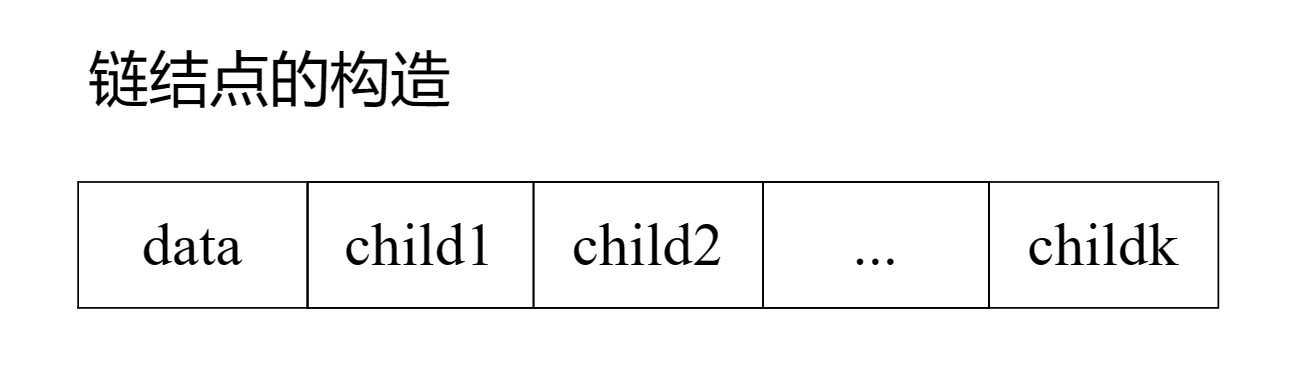
缺点:存储空间比较浪费
对于具有n个结点且度为k的树,空指针域的数目为n*(k-1)+1

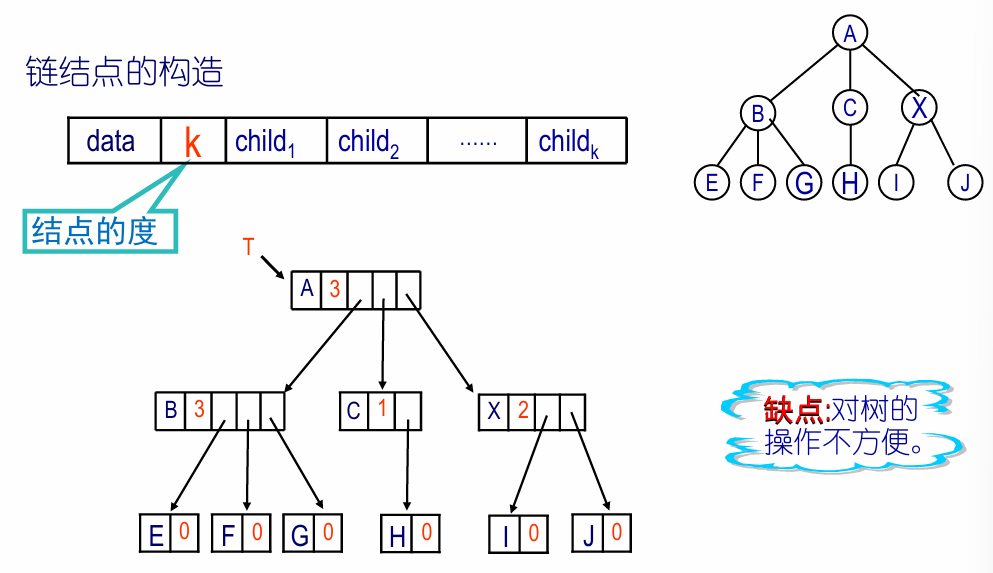
2.1.2 不定长结点的多重链表结构
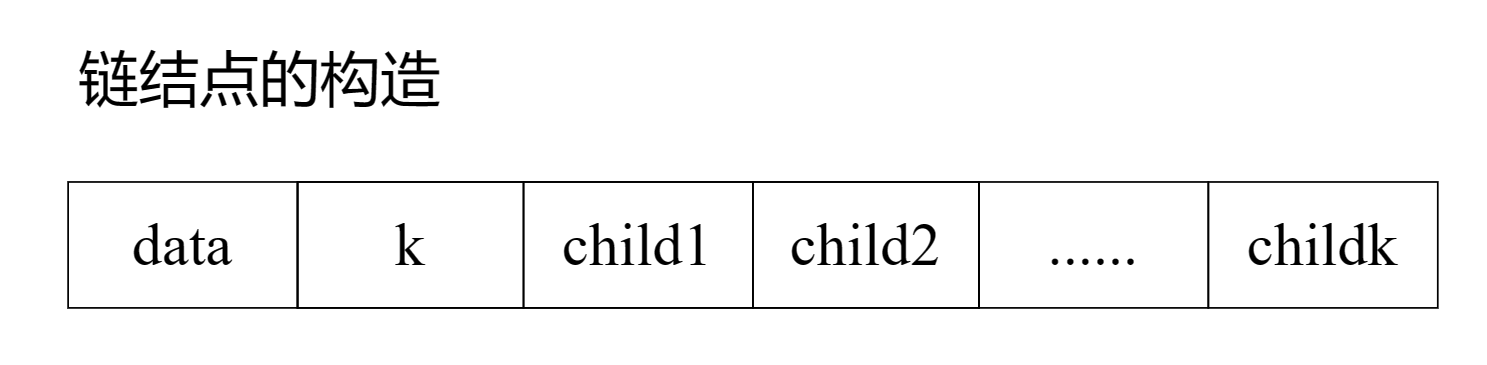
缺点:对数的操作不方便
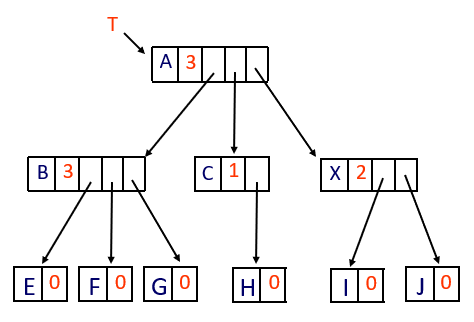
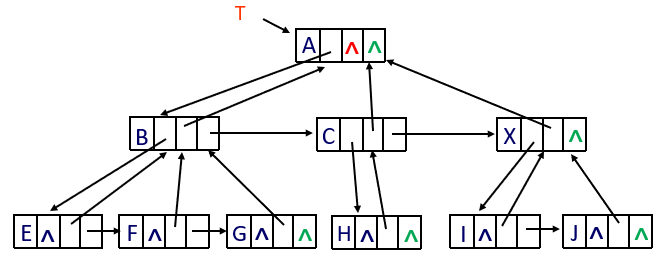
2.2 三重链表结构
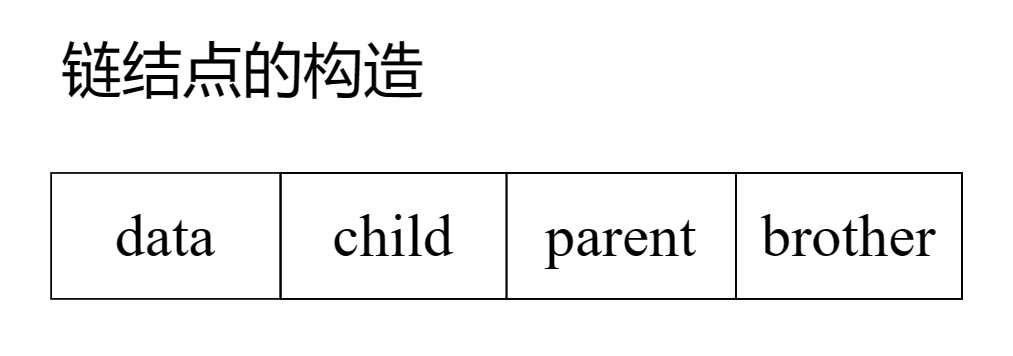
data为数据域;child为指针域,指向该节点的第一个孩子结点;parent为指针域,指向该结点的双亲结点;brother为指针域,指向右边的第一个兄弟结点。
3 二叉树
3.1 二叉树的定义
二叉树是n>=0个结点的有穷集合D与D上关系的集合R构成的结构,记为
T。当n=0时,称T为空二叉树;否则,它为包含了一个根结点以及两棵不相交的、分别称之为左子树与右子树的二叉树。二叉树是有序树。
二叉树的基本形态:
辨析:
- 度为2的树是二叉树。
- 度为2的有序树是二叉树。
(√) 子树有严格的左右之分且度<=2的树是二叉树。
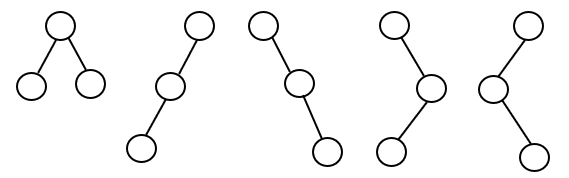
具有3个结点的二叉树可以有5种形态。
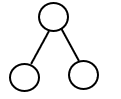
具有3个结点的树可以有1种形态。
3.2 两种特殊形态的二叉树
满二叉树
若一棵二叉树中的结点,或者为叶结点,或者具有两棵非空子树,并且叶结点都集中在二叉树的最下面一层。这样的二叉树为满二叉树。
完全二叉树
若一棵二叉树中只有最下面两层的结点的度可以小于2,并且最下面一层的结点(叶结点)依次排列在该层从左至右的位置上.这样的二叉树为完全二叉树。
3.3 二叉树的性质
具有n个结点的非空二叉树共有n-1个分支。
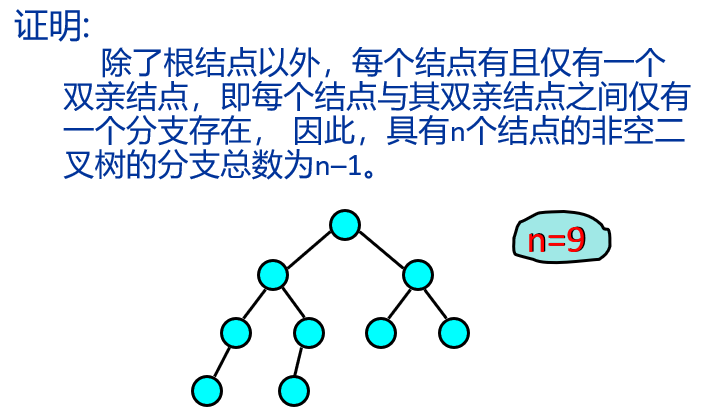
非空二叉树的第i层最多有2i–1个结点(i>=1)。

深度为h的非空二叉树最多有2h–1个结点。深度为h的完全二叉树至少有2h-1个结点。
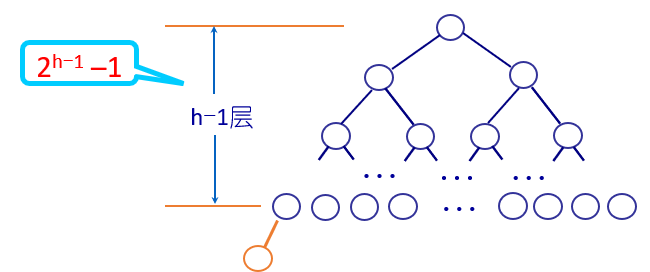
若非空二叉树有n0个叶结点,有n2个度为2的结点,则n0=n2+1。

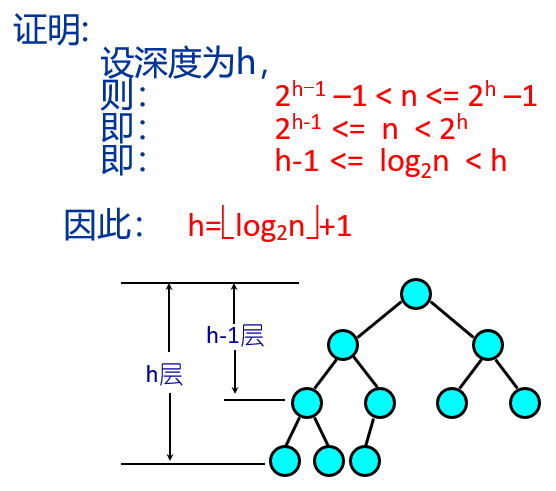
具有n个结点的非空完全二叉树的深度为h= ⌊log2n⌋+1。
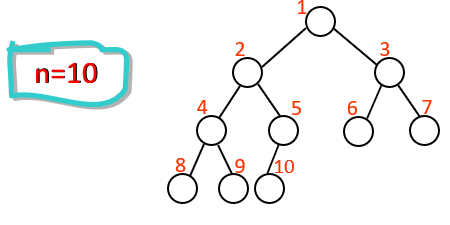
若对具有n个结点的完全二叉树按照层次从上到下,每层从左到右的顺序进行编号, 则编号为i(i≥1)的结点具有以下性质:
当i=1,则编号为i的结点为二叉树的根结点;
若i>1,则编号为i的结点的双亲的编号为⌊i/2⌋;
若2i>n,则编号为i的结点无左子树;
若2i>n,则编号为i的结点的左孩子的编号为2i;
若2i+1>n,则编号为i的结点无右子树;
若2i+1≤n,则编号为i的结点的右孩子的编号为2i+1。
若对具有n个结点的完全二叉树按照层次从上到下,每层从左到右的顺序进行编号, 则编号为i(i≥0)的结点具有以下性质:
当i=0,则编号为i的结点为二叉树的根结点;
若i>0,则编号为i的结点的双亲的编号为⌊(i-1)/2⌋;
若2i+1≥n,则编号为i的结点无左子树;
若2i+1<n,则编号为i的结点的左孩子的编号为2i+1;
若2i+2≥n,则编号为i的结点无右子树;
若2i+2<n,则编号为i的结点的右孩子的编号为2i+2。
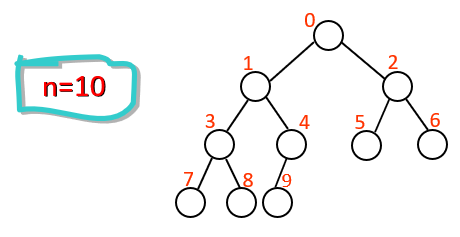
例:

3.4 二叉树的基本操作
INITAL(T):初始(创建)一棵二叉树。ROOT(T)或ROOT(x):求二叉树T的根结点,或求结点x所在二叉树的根结点。PARENT(T, x):求二叉树T中结点x的双亲结点。若x是二叉树的根结点,或二叉树中不存在结点x,则返回“空”。LCHILD(T, x)或RCHILD(T, x):分别求二叉树T中结点x的左孩子结点或右孩子结点。LDELETE(T, x)或RDELETE(T, x):分别删除二叉树T中以结点x为根的左子树或右子树。TRAVERSE(T):按照某种次序(或原则)依次访问二叉树T中各个结点,得到由该二叉树的所有结点组成的序列。LAYER(T, x):求二叉树中结点x所处的层次。DEPTH(T):求二叉树T的深度。DESTROY(T):销毁一棵二叉树。删除T的所有结点,并释放结点空间,使之成为一棵空二叉树。
3.5 *二叉树与树、树林之间的转换
树->二叉树
- 在所有相邻的兄弟结点之间分别加一条连线;
- 对于每一个分支结点,除了其最左孩子外,删除该结点与其他孩子结点之间的连线;
- 以根结点为轴心,顺时针旋转45。
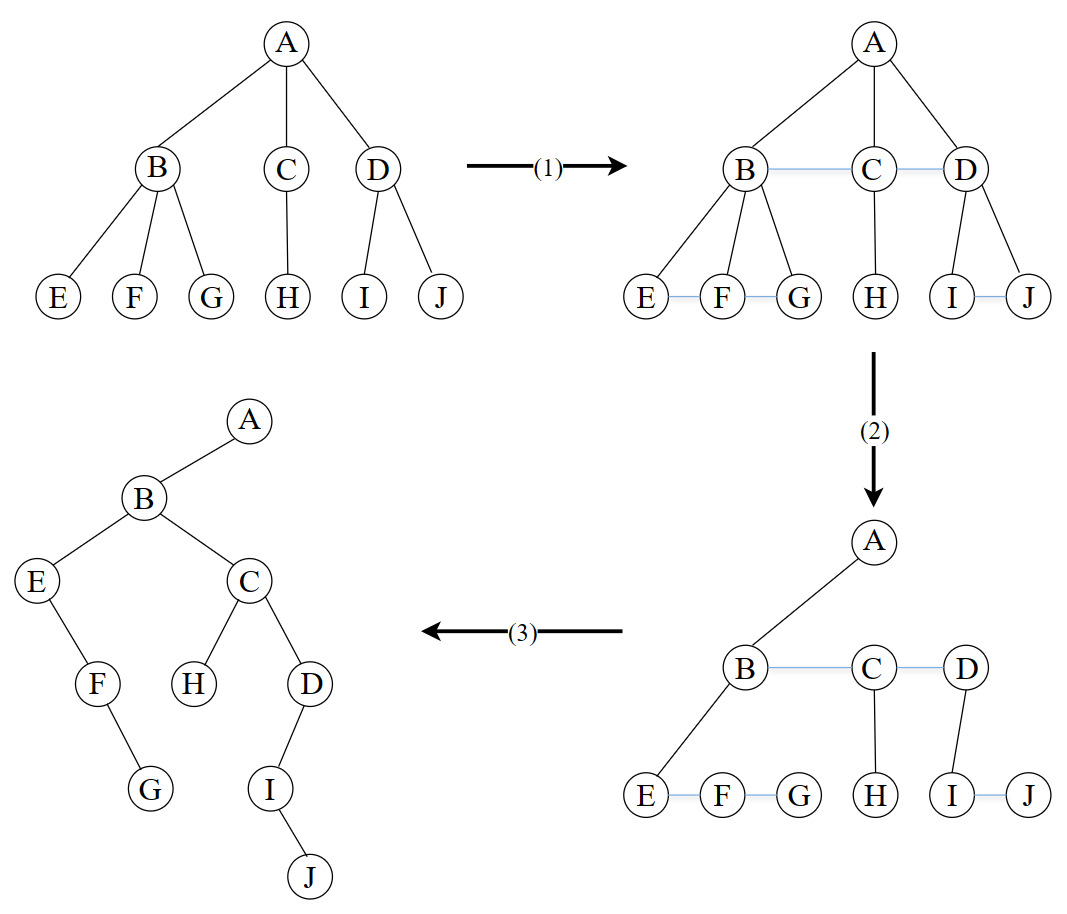
树林->二叉树
- 分别将树林中每一棵树转换为一棵二叉树;
- 从最后那一棵二叉树开始,依次将后一棵二叉树的根结点作为前一棵二叉树的根结点的右孩子,直到所有二叉树都这样处理。这样得到的二叉树的根结点是树林中第一棵二叉树的根结点。

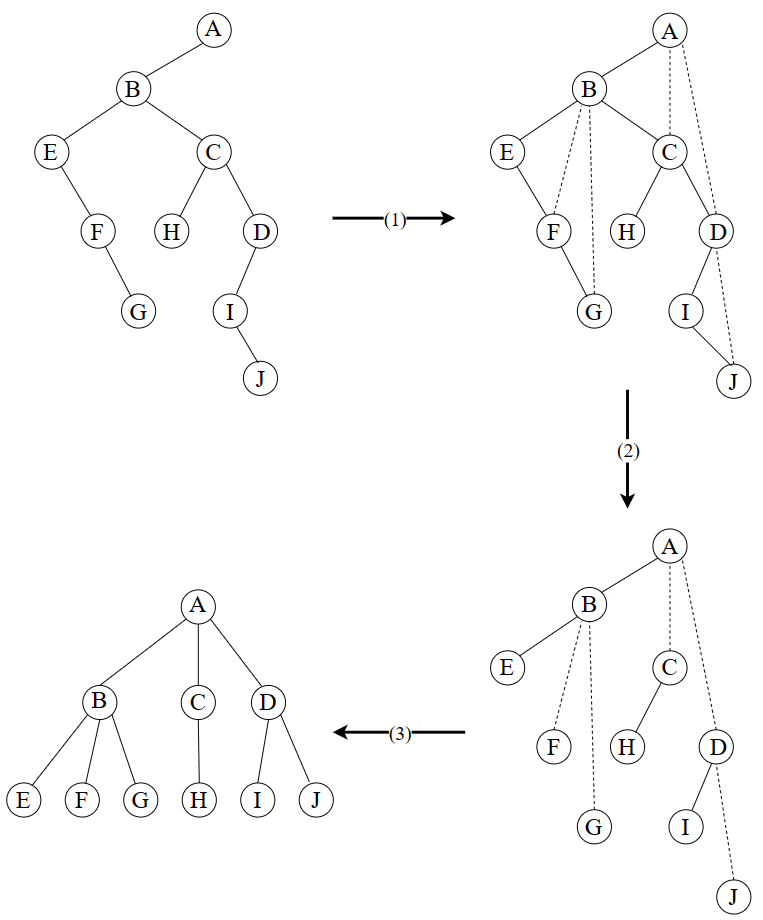
二叉树还原为树(前提:由一棵树转换而来)
- 若某结点是其双亲结点的左孩子,则将该结点的右孩子以及当且仅当连续地沿此右孩子的右子树方向的所有结点都分别与该结点的双亲结点用一根虚线连接;
- 去掉二叉树中所有双亲结点与其右孩子的连线;
- 规整图形(即使各结点按照层次排列),并将虚线改成实线。
4 二叉树的存储结构
4.1 二叉树的顺序存储结构
完全二叉树的顺序存储结构
根据完全二叉树的性质6,对于深度为h的完全二叉树,将树中所有结点的数据信息按照编号的顺序依次存储到一维数组BT[0...2h-2]中,由于编号与数组下标一一对应,该数组就是该完全二叉树的顺序存储结构。
对于一个下标为i的结点,其父结点下标为(i-1)/2;其子结点下标为:2i+1, 2i+2
一般二叉树的顺序存储结构
对于一般二叉树, 只须在二叉树中“添加”一些实际上二叉树中并不存在的“虚结点”(可以认为这些结点的数据信息为空), 使其在形式上成为一棵“完全二叉树”, 然后按照完全二叉树的顺序存储结构的构造方法将所有结点的数据信息依次存放于数组BT[0..2h-2]中。
结论:
- 顺序存储结构比较适合满二叉树,或者接近于满二叉树的完全二叉树,对于一些称为“退化二叉树”的二叉树,顺序存储结构的空间开销浪费的缺点表现比较突出。
- 顺序存储结构便于结点的检索(由双亲查子、由子查双亲)。
- 顺序存储结构由于需要事先分配存储空间,对于动态数据容易溢出。
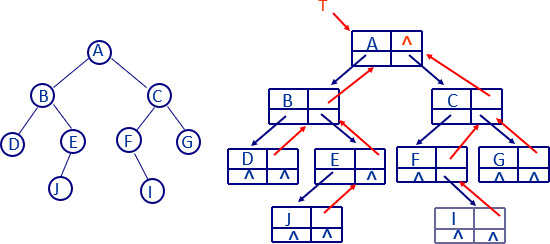
4.2 二叉树的链式存储结构
二叉链表
定长结点的多重链表结构
链结点的构造:

其中
data为数据域;left和right分别为指向左、右子树的指针域。结点类型定义
1
2
3
4
5
6
7struct node{
Datatype data;
struct node *left, *right;
};
typedef struct node BTNode;
typedef struct node *BTNodeptr;
BTNodeptr T, p, q;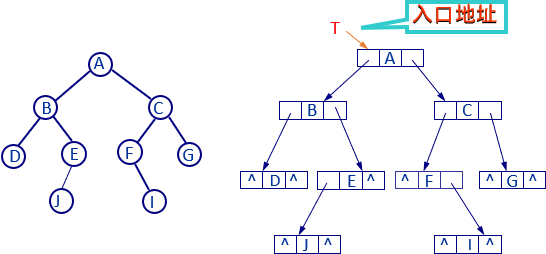
不定长结点的多重链表结构
*三叉链表
链结点的构造:

其中,
data为数据域,parent为指向双亲结点的指针;left和right分别为指向左、右孩子结点的指针。优点:当找到一个结点时,可以很方便的得到其所有祖先结点,或得到从根到该结点的路径。
5 典型操作(遍历等)
5.1 二叉树的遍历
定义:按照一定的顺序(原则)对二叉树中每一个结点都访问一次(仅访问一次),得到一个由该二叉树的所有结点组成的序列,这一过程称为二叉树的遍历。
常用的遍历方法
- 前序遍历(DLR)
- 中序遍历(LDR)
- 后序遍历(LRD)
- 按层次遍历
其中L表示遍历左子树,R表示遍历右子树,D表示访问根结点。前序、中序及后序遍历实质为深度优先算法(DFS),层次遍历为一种广度优先算法(BFS)。
可以利用前序序列和中序序列恢复二叉树,可以利用中序序列和后序序列恢复二叉树,不能利用前序序列和后序序列恢复二叉树。
5.1.2 前序遍历
原则:若被遍历的二叉树非空,则
- 访问根结点
- 以前序遍历原则遍历根结点的左子树;
- 以前序遍历原则遍历根结点的右子树。
1 | |
5.1.3 中序遍历
原则:若被遍历的二叉树非空,则
- 以中序遍历原则遍历根结点的左子树;
- 访问根结点;
- 以中序遍历原则遍历根结点的右子树。
1 | |
5.1.4 后序遍历
原则:若被遍历的二叉树非空,则
- 以后序遍历原则遍历根结点的左子树;
- 以后序遍历原则遍历根结点的右子树;
- 访问根结点。
1 | |
5.1.5 按层次遍历
原则:若被遍历的二叉树非空,则按照层次从上到下,每一层从左到右依次访问节点。
1 | |
5.1.6 由遍历序列恢复二叉树
已知前序序列和中序序列,恢复二叉树:在前序序列中确定根; 到中序序列中分左右。
已知中序序列和后序序列,恢复二叉树:在后序序列中确定根; 到中序序列中分左右。
5.2 树的遍历
前序遍历
原则:若被遍历的树非空,则
- 访问根结点;
- 依次按前序遍历方式遍历根结点每一棵子树。
后序遍历
原则:若被遍历的树非空,则
- 依次按后序遍历方式遍历根结点每一棵子树;
- 访问根结点。
深度优先遍历算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#define MAXD 3 //树的度
struct node{
Datatype data;
struct node *next[MAXD];
};
typedef struct node TNode;
typedef struct node *TNodeptr;
void DFStree(TNodeptr t){
int i;
if(t!=NULL){
VISIT(t); /* 访问t指向结点 */
for(i=0;i<MAXD; i++)
if(t->next[i] != NULL)
DFStree(t->next[i]);
}
}广度优先遍历算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22#define MAXD 3 //树的度
struct node{
Datatype data;
struct node *next[MAXD];
};
typedef struct node TNode;
typedef struct node *TNodeptr;
void BFStree(TNodeptr t){
TNodeptr p;
int i;
if(t!=NULL){
enQueue(t);
while(!isEmpty()){ // 若队列不空
p= deQueue();
VISIT(p);
for(i=0; i<MAXD; i++) // 依次访问p指向的子结点
if(p->next[i] != NULL)
enQueue(p);
}
}
}
5.3 二叉树的拷贝
树拷贝时先拷贝当前结点,再拷贝子结点(同前序遍历)
1 | |
5.4 二叉树的删除
树删除时先删除子结点,再删除当前结点。(同后序遍历)
1 | |
5.5 二叉树的高度
1 | |
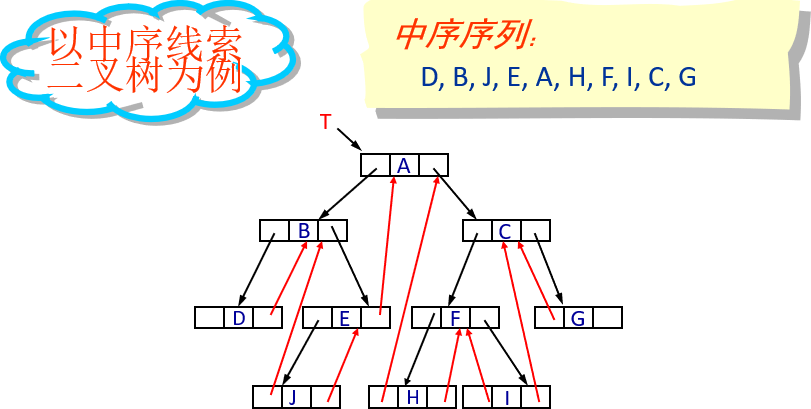
6 *线索二叉树(Threaded Binary Tree)
6.1 基本概念
利用二叉链表中空的指针域指出结点在某种遍历序列中的直接前驱或直接后继。指向前驱和后继的指针称为线索,加了线索的二叉树称为线索二叉树。
6.2 线索二叉树的构造
利用链结点的空的左指针域存放该结点的直接前驱的地址,空的右指针域存放该结点直接后继的地址;而非空的指针域仍然存放结点的左孩子或右孩子的地址。
指针与线索的区分
- 法1:

- 法2:不改变链结点的构造,而是在作为线索的地址前加一个负号,即“负地址”表示线索,“正地址”表示指针。
- 法1:
线索二叉树链结点类型定义:
1
2
3
4
5
6
7struct node{
Datatype data;
struct node *left, *right;
char lbit, rbit;
};
typedef struct node TBTNode;
typedef struct node *TBTNodeptr;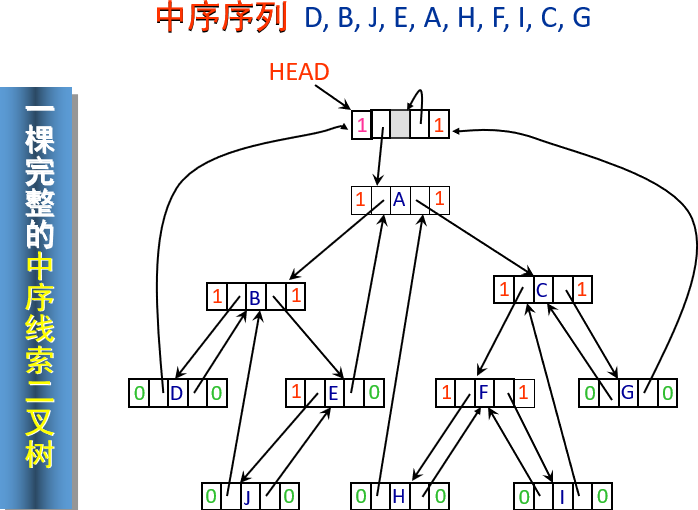
6.3 线索二叉树的应用
为中序线索二叉树确定地址为x的结点的直接后继
规律:
- 当
x->rbit=0时,x->right指出的结点就是x的直接后继结点。 - 当
x->rbit=1时,沿着x的右子树的根的左子树方向查找,直到某结点的left域为线索时, 此结点就是x结点直接后继结点。
- 当
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// 确定x的直接后继
TBTNodeptr insucc(TBTNodeptr x){
TBTNodeptr s;
s=x->right;
if(x->rbit==1)
while (s->lbit==1)
s=s->left;
return(s);
}
// 利用上面函数实现非递归中序遍历
void torder(TBTNodeptr head){
TBTNodeptr p=head;
while(1){
p=insucc(p);
if(p==head)
break;
VISIT(p);
}
}
6.4 线索二叉树的建立
建立线索的规矩:
prior:指向前一次访问结点p:指向当前访问结点若当前访问的结点的左指针域为空,则它指向
prior指的结点,同时置lbit为0,否则,置lbit为1;若
prior所指结点的右指针域为空,则它指向当前访问的结点,同时置rbit为0,否则,置rbit为1。p=NULL时遍历结束,将prior->right指向头结点,并置prior->rbit为0。
代码实现(对根结点
root引领的树进行中序线索化)递归版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31TBTNodeptr piror;
TBTNodeptr threading(TBTNodeptr root){
TBTNodeptr head;
head = (TBTNodeptr)malloc(sizeof(TBTNode));
head->left = root; head->right = head; head->lbit = head->rbit=1;
piror = head;
inThreading(root);
piror->right = head; piror->rbit = 0;
return head;
}
// 中序遍历进行中序线索化 piror是一个全局变量,初始时,piror指向树head结点
void inThreading(TBTNodeptr p){
if(p != NULL) {
inThreading(p->left); //递归左子树线索化
if(p->left == NULL) { //没有左孩子
p->lbit = 0; //前驱线索
p->left = prior; //左孩子指针指向前驱
}else{
p->lbit = 1;
}
if(prior->right == NULL) { //前驱没有右孩子
prior->rbit = 0; //后继线索
prior->right = p; //前驱右孩子指向后继
}else{
prior->rbit = 1;
}
prior = p; //保持prior指向p的前驱
inThreading(p->right); //递归右子树线索化
}
}非递归版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40#define NodeNum 100 // 定义二叉树中结点最大数目
TBTNodeptr inthread(TBTNodeptr t){
TBTNodeptr head, p=t, prior, stack[NodeNum];
int top=-1;
head=(TBTNoteptr)malloc(sizeof(TBNode));
// 申请线索二叉树的头结点空间
head->left=t;
head->right=head;
head->lbit=1;
prior=head; // 假设中序序列的第1个结点的“前驱”为头结点
do{
for(; p!=NULL; p=p->left) // p移到左孩子结点
stack[++top]=p; // p指结点的地址进栈
p=stack[top--]; // 退栈
if(p->left==NULL){ // 若当前访问结点的左孩子为空
p->left=prior; // 当前访问结点的左指针域指向前一次访问结点
p->lbit=0; // 当前访问结点的左标志域置0(表示地址为线索)
}else{
p->lbit=1; // 当前访问结点的左标志域置1(表示地址为指针)
}
if(prior->right==NULL){ // 若前一次访问的结点的右孩子为空
prior->right=p;
// 前一次访问结点的右指针域指向当前访问结点
prior->rbit=0;
// 前一次访问结点的右标志域置0(表示地址为线索)
}else{
prior->rbit=1;
// 前一次访问结点的右标志域置1(表示地址为指针)
}
prior=p; // 记录当前访问的结点的地址
p=p->right; // p移到右孩子结点
}while(!(p==NULL && top==-1));
prior->right=head; // 设中序序列的最后结点的后继为头结点
prior->rbit=0; // prior指结点的右标志域置0(表示地址为线索)
return head; // 返回线索二叉树的头结点指针
}二叉树线索化的好处:线索化二叉树等于将一棵二叉树转变成了一个双向链表,这为二叉树结点的插入、删除和查找带来了方便。在实际问题中,如果所用的二叉树需要经常遍历或查找结点时需要访问结点的前驱和后继,则采用线索二叉树结构是一个很好的选择。将二叉树线索化可以实现不用栈的树深度优先遍历算法。
7 二叉查找树(二叉搜索树、二叉排序树)(Binary Search Tree, BST)
适合于数据量大且无序的数据,如单词词频统计(单词索引)等。
7.1 二叉查找树的定义
二叉查找树或者为空二叉树, 或者为具有以下性质的二叉树:
- 若根结点的左子树不空, 则左子树上所有结点的值都小于根结点的值;
- 若根结点的右子树不空, 则右子树上所有结点的值都大于或等于根结点的值;
- 每一棵子树分别也是二叉查找树。
7.2 二叉查找树的建立(逐点插入法)
规律
设K=( k1, k2, k3, … , kn )为具有n个数据元素的序列。从序列的第一个元素开始,依次取序列中的元素,每取一个元素ki,按照下述原则将ki插入到二叉树中:
- 若二叉树为空,则ki作为该二叉树的根结点;
- 若二叉树非空,则将ki与该二叉树的根结点的值进行比较,若ki小于根结点的值,则将ki插入到根结点的左子树中;否则,将ki插入到根结点的右子树中。
- 将ki插入到左子树或者右子树中仍然遵循上述原则(递归)。
代码实现(将一个数据元素
item插入到根指针为root的二叉排序树中)递归算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33#include <stdio.h>
typedef int Datatype;
struct node {
Datatype data;
struct node *left, *right;
};
typedef struct node BTNode, *BTNodeptr;
BTNodeptr insertBST(BTNodeptr p, Datatype item);
int main(){
int i, item;
BTNodeptr root=NULL;
for(i=0; i<10; i++){ //构造一个有10个元素的BST树
scanf(“%d”, &item);
root = insertBST(root, item);
}
return 0;
}
BTNodeptr insertBST(BTNodeptr p, Datatype item){
if(p == NULL){ // 如果二叉树为空
p = (BTNodeptr)malloc(sizeof(BTNode));
p->data = item;
p->left = p->right = NULL;
}
else if(item < p->data) // 小于根结点放左边
p->left = insertBST(p->left, item);
else if(item > p->data) // 大于根结点放右边
p->right = insertBST(p->right,item);
else
do-something; //树中存在该元素
return p;
}非递归算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33BTNodeptr Root=NULL; //Root是一个全局变量
void insertBST(Typedata item){
BTNodeptr p, q;
p=(BTNodeptr)malloc(sizeof(BTNode));
p->data=item;
p->left=NULL;
p->right=NULL;
if(Root==NULL){ // 根结点为空
Root=p;
}else{
q=Root;
while(1){ /* 比较值的大小 */
/* ,大于向右 */
if(item < q->data){ // 小于向左
if(q->left == NULL){
q->left=p;
break;
}else{
q = q->left;
}
}else if(item > q->data){ // 大于向右
if(q->right==NULL){
q->right=p;
break;
}else{
q=q->right;
}
}else{
/* do-something */
}
}
}
}通过调用非递归插入算法建立二叉查找树的(主)算法
1
2
3
4
5
6
7BTNodeptr Root=NULL;
void sortTree(Datatype k[ ], int n) {
int i;
for(i=0; i<n; i++)
insertBST(k[i]);
return ;
}
7.3 二叉查找树的删除
- 被删除节点为叶节点,则直接删除;
- 被删除结点无左子树,则用右子树的根结点取代被删除结点;
- 被删除结点无右子树,则用左子树的根结点取代被删除结点。
- 被删除结点的左、右子树都存在,则用被删除结点的右子树中值最小的结点(或被删除结点的左子树中值最大的结点)取代被删除结点。
- 懒惰删除(lazy deletion):当一个元素要被删除时,它仍留在树中,而是只做一个被删除的记号。如果删除的次数不多,则通常使用的策略是懒惰删除。
7.4 二叉查找树的查找
查找过程
- 若二叉查找树为空,则查找失败,查找结束。
- 若二叉查找树非空,则将被查找元素与二叉排序树的根结点的值进行比较,
- 若等于根结点的值,则查找成功,结束;
- 若小于根结点的值,则到根结点的左子树中重复上述查找过程;
- 若大于根结点的值,则到根结点的右子树中重复上述查找过程;
- 直到查找成功或者失败。
- 若查找成功,给出被查找元素所在结点的地址;若查找失败,给出信息NULL。
代码实现
非递归算法
1
2
3
4
5
6
7
8
9
10
11
12BTNodeptr searchBST(BTNodeptr t,Datatype key){
BTNodeptr p = t;
while(p!=NULL){
if(key == p->data)
return p; // 查找成功
if(key > p->data)
p=p->right; // 将p移到右子树的根结点
else
p=p->left; // 将p移到左子树的根结点
}
return NULL; // 查找失败
}递归算法
1
2
3
4
5
6
7
8
9
10
11
12BTNodeptr searchBST( BTNodeptr t, Datatype key ){
if(t!=NULL){
if(key == t->data)
return t; // 查找成功
if(key > t->data)
return searchBST(t->right, key); // 查找T的右子树
else
return searchBST(t->left, key); // 查找T的左子树
}
else
return NULL; // 查找失败
}查找效率
平均查找长度ASL:确定一个元素在树中位置所需要进行的元素间的比较次数的期望值(平均值)。 \[ ASL = \sum_{i=1}^{k} p_ic_i \] 其中n表示二叉树中结点的总数;pi表示查找第i个元素的概率;ci表示查找第i个元素需要进行的元素之间的比较次数。
8 平衡二叉树(Adelson-Velskii and Landis, AVL)
二叉查找树的缺陷:树的形态无法预料、随意性大。得到的可能是一个不平衡的树,即树的深度差很大。丧失了利用二叉树组织数据带来的好处。
平衡二叉树又称AVL树。它或者是一棵空树,或者是具有下列性质的二叉树:
它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。若将二叉树的平衡因子定义为该结点左子树深度减去右子树深度,则平衡二叉树上所有结点的平衡因子只可能是-1、0和1。
例
1 已知二叉查找树采用二叉链表存储结构,根结点地址为T,请写一非递归算法,打印数据信息为item的结点的所有祖先结点。(设该结点存在祖先结点)
1 | |
- 若需要保存祖先结点序列(即结点路径),可以设一个栈保存路径节点,或设一个指向父结点的指针
2 获取一个普通二叉树的数据信息为item的结点的所有祖先结点。
1 | |
3 词频统计——二叉查找树
3.1 问题
编写程序统计一个文件中每个单词的出现次数(词频统计),并按字典序输出每个单词及出现次数。
3.2 算法分析
本问题算法很简单,基本上只有查找和插入操作。
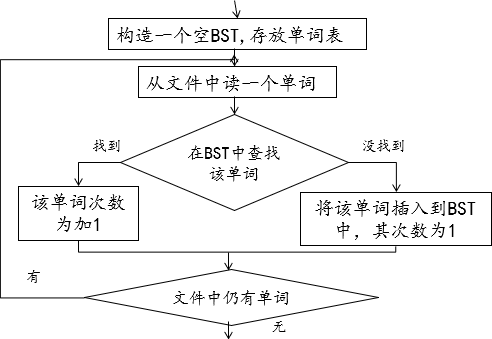
3.3 代码实现
1 | |
3.4 拓展
如果对统计好的词频按单词频率序输出该怎么办(如何对非线性数据进行排序?)(实际应用通常是这么要求的)
9 *堆(heap)——二叉树的应用
9.1 堆的基本性质
堆是一种特殊类型的二叉树,具有以下两个性质:
- 每个节点的值大于(或小于)等于其每个子节点的值;
- 该树完全平衡,其最后一层的叶子都处于最左侧的位置。
满足上面两个性质定义的是大顶堆(max heap)(或小顶堆(min heap))。即大顶堆的根节点包含了最大的元素,小顶堆的根节点包含了最小的元素。
由于堆是一个完全树,一般采用数组实现,对于一个下标为i的结点:
- 其父结点下标为:(i-1)/2
- 其子结点下标为:2i+1, 2i+2
- (如果是大顶堆):heap[i] ≧heap[2*i+1]; heap[i] ≧heap[2*i+2]
堆结构的最大好处是元素查找、插入和删除效率高(O(log2n))
堆的主要应用:
- 可用来实现优先队列(Priority Queue)
- 用来实现一种高效排序算法-堆排序(Heap Sort),在排序一讲中详细介绍
9.2 堆的基本操作(以大顶堆为例)
插入算法
1
2
3
4heapInsert(e)
将e放在堆的末尾;
while e 不是根 && e > parent(e)
e 与其父节点交换;删除算法(获取堆顶元素,并从堆中删除)
1
2
3
4
5
6
7
8heapDelete() //取堆顶(树根)元素
从根节点提取元素;
将最后一个叶节点中的元素放到要删除的元素位置;
删除最后一个叶节点;
//根的两个子树都是堆
p = 根节点;
while p 不是叶节点 && p < 它的任何子节点
p与其较大的子节点交换;
9.3 堆的构造
- 自顶向下:从空堆开始,按顺序向堆中添加(用
headinsert函数)元素 - 自底向上:首先从底层开始构造较小的堆,然后再重复构造较大的堆。(算法将在堆排序一节中介绍)
9.4 堆的典型应用
- 优先队列(Priority queue):与传统队列不同的是下一个服务对象是队列中优先级最高的元素。优先队列常用的实现方式是用堆,其最大好处是管理元素的效率高(O(log2 N))。优先队列是计算机中常用的一种数据结构,如操作系统中进程调度就是基于优先队例。
- 堆排序(Heap sort):一种基于堆的高效(O(nlog2 n))的排序算法。
10 表达式树(expression tree)——二叉树的应用
10.1 表达式树的定义
表达式树是一种特殊类型的树,其叶结点是操作数(operand),而其它结点为操作符(operator):
- 由于操作符一般都是双目的,通常情况下该树是一棵二叉树;
- 对于单目操作符(如++),其只有一个子结点。
例:

主要应用:编译器用来处理程序中的表达式
10.2 表达式树的构造
表达式树是这样一种树,非叶节点为操作符,叶节点为操作数,对其进行遍历可计算表达式的值。由后缀表达式生成表达式树的方法如下:
- 从左至右从后缀表达式中读入一个符号:
- 如果是操作数,则建立一个单节点树并将指向该节点的指针推入栈中;(栈中元素为树节点的指针)
- 如果是运算符,就从栈中弹出指向两棵树T1和T2的指针(T1先弹出)并形成一棵新树,树根为该运算符,它的左、右子树分别指向T2和T1,然后将新树的指针压入栈中。
- 重复步骤1,直到后缀表达式处理完。
11 哈夫曼(Huffman)树及其应用
11.1 哈夫曼树的基本概念
一些定义
结点之间的路径:这两个结点之间的分支
路径长度:路径上经过的分支数目
树的路径长度:根结点到所有结点的路径长度之和
树的带权路径长度:若给具有m个叶结点的二叉树的每个叶结点赋予一个权值,则该二叉树的带权路径长度定义为 \[ WPL =\sum_{i=1}^{M} w_il_i \] 其中,wi为第i个叶结点被赋予的权值,li为第i个叶结点的路径长度。
哈夫曼树的定义:给定一组权值,构造出的具有最小带权路径长度的二叉树称为哈夫曼树。
哈夫曼树的特点
- 权值越大的叶结点离根结点越近,权值越小的叶结点离根结点越远;
- 无度为1的结点
- 哈夫曼树不是唯一的
11.2 哈夫曼树的构造
对于给定的权值W={ w1, w2,..., wm},构造出树林F={ T1, T2,..., Tm},其中,Ti(1≤i≤m)为左、右子树为空,且根结点(叶结点)的权值为wi的二叉树。
将F中根结点权值最小的两棵二叉树合并成为一棵新的二叉树,即把这两棵二叉树分别作为新的二叉树的左、右子树,并令新的二叉树的根结点权值为这两棵二叉树的根结点的权值之和,将新的二叉树加入F的同时从F中删除这两棵二叉树。
重复步骤2,直到F中只有一棵二叉树。
11.3 例 Huffman编码
11.3.1 背景:Huffman编码
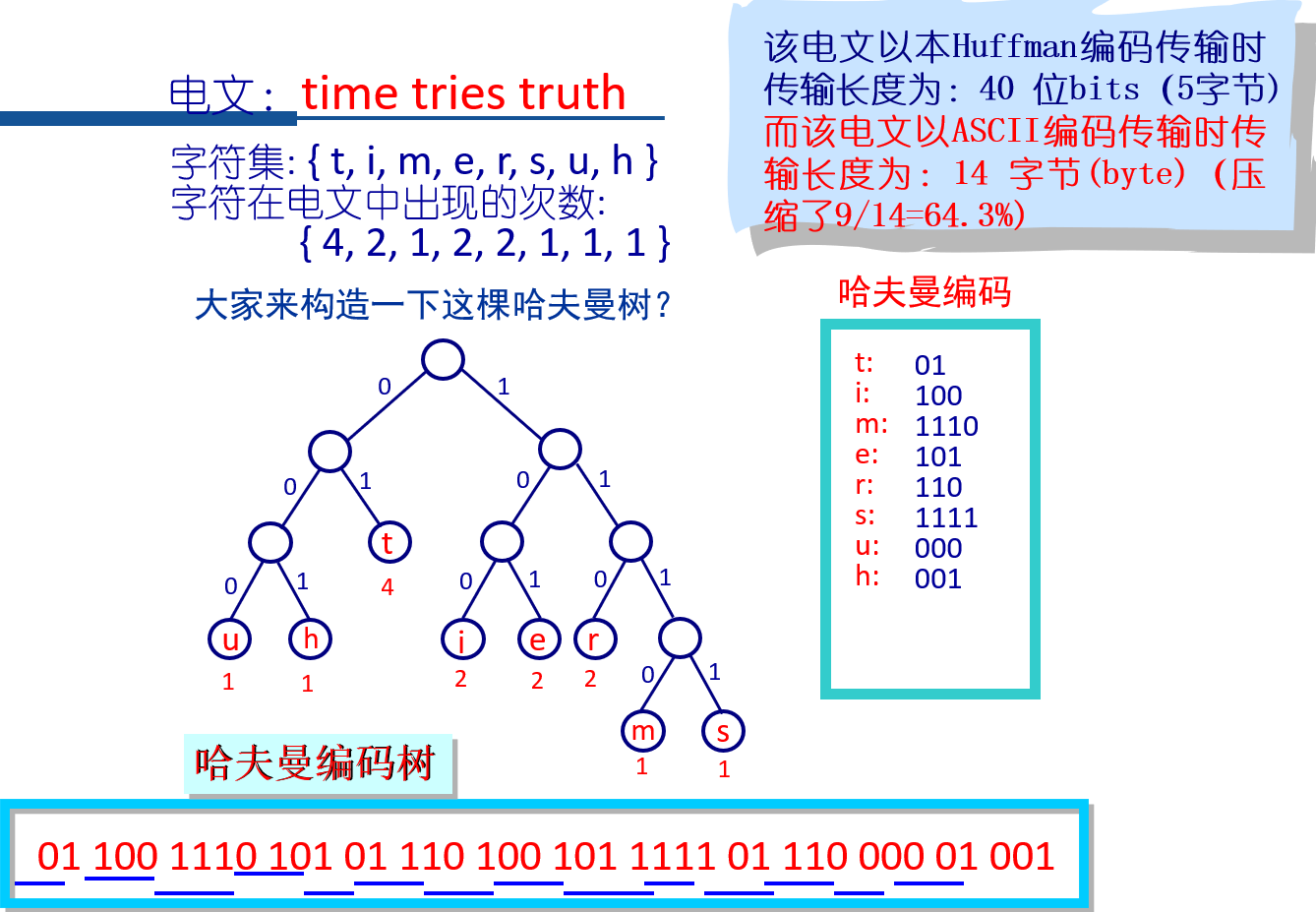
11.3.2 问题提出
- 编写一个程序采用Huffman编码实现对一个文件的压缩。
- 要求:首先读取文件,对文件中出现的每个字符进行字符频率统计,然后根据频率采用Huffman方法对每个字符进行编码,最后根据新字符编码表输出文件。
11.3.3 问题分析

11.3.4 算法设计
定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#define MAXSIZE 32
struct cc { //字符及出现次数结构
char c;
int count;
} ;
struct tnode { //Huffman树结构
struct cc ccount; //字符及出现次数
struct tnode *left, *right; //树的左右节点指针
struct tnode *next; //一个有序链表的节点指针
} ;
struct tnode *Head = NULL; //一个有序链表的头节点,也是最后Huffman树的根节点
char Huffman[MAXSIZE]; //用于生成Huffman编码
char HCode[128][MAXSIZE]; //字符的Huffman编码,Hcode[0]为文件结束符的编码
例如:Hcode['a']表示字符a的Huffman编码串。为了生成Huffman树,首先根据字符统计结果生成一个有序链表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 字符频率统计:
struct cc ccount[128];
while( (c=fgetc(fp)) != EOF){
ccount[c].c=c;
ccount[c].count++;
}
// 根据字符统计结果生成一个有序链表:
struct tnode *p;
for(i=0; i<128; i++){
if(ccount[i].count != 0){
p = (struct tnode *)malloc(sizeof(struct tnode));
p->ccount = ccount[i];
p->left = p->right = p->next = NULL;
insertSortLink(p);
}
}按Huffman树生成算法,由有序表构造Huffman树:
1
2
3
4
5
6
7
8
9while(Head->next != NULL){
p = (struct tnode *)malloc(sizeof(struct tnode));
p ->ccount.count = Head->ccount.count + Head->next->ccount.count;
p->left = Head;
p->right = Head->next; /*将新树的根结点加入到有序结点链表中*/
p->next = NULL;
Head = Head->next->next;
insertSortLink(p);
}遍历(前序)Huffman树,为每个叶结点生成Huffman编码:
1
2
3
4
5
6
7
8
9
10
11void createHCode(struct tnode *p, char code, int level){
if(level != 0)
Huffman[level-1] = code;
if(p->left == NULL && p->right == NULL){
Huffman[level] ='\0';
strcpy(HCode[p->ccount.c], Huffman);
}else{
createHCode(p->left,'0', level+1);
createHCode(p->right,'1', level+1);
}
}第四步:根据Huffman编码,遍历源文件,生成相应压缩文件:
下面通过实例来说明:
原始文件input.txt中内容以“I will…”开始,依据所生成的Huffman码表,字母I对应的Huffman编码串为“0101111”,空格对应“111”,w对应“1001110”,i对应“01010”,l对应“11001”。因此,将其转换后得到一个Huffman编码串“01011111111001110010101100111001…”,由于在C中,最小输出单位是字节(共8位),因此,要通过C语言的位操作符将每8个01字符串放进一个字节中,如第一个8字符串“01011111”中的每个0和1放入到一个字符中十六进制(即
printf(”%x”,c)输出时,屏幕上将显示5f)(如下图所示)。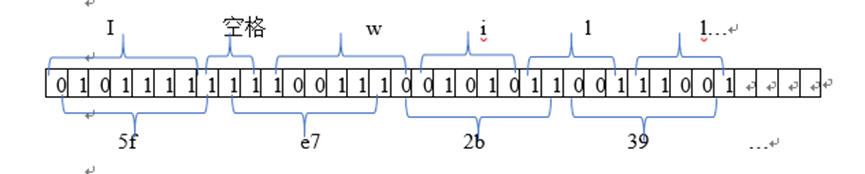
下面程序段将Huffman编码串每8个字符串放入一个字节(字符变量
hc)中:1
2
3
4
5
6
7
8char hc;
for(i=0; s[i] != '\0'; i++){
hc = (hc << 1) | (s[i]-'0');
if((i+1)%8 == 0) {
fputc(hc, obj); //输出到目标(压缩)文件中
printf("%x", hc);//按十六进制输出到屏幕上
}
}完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21void madeHZIP(FILE *src, FILE *obj){
unsigned char *pc,hc=0;
int c=0,i=0;
fseek(src,0, SEEK_SET); //从src文件头开始
do{
c=fgetc(src); //依次获取源文件中每个字符
if (c == EOF)
c=0; //源文件结束
for(pc = HCode[c]; *pc != '\0'; pc++){ //转换为huffman码
hc = (hc << 1) | (*pc-'0'); i++;
if(i==8){ //每满8位输出一个字节
fputc(hc,obj);
i = 0;
}
}
if(c==0 && i!=0){ //处理文件结束时不满一个字节的情况
while(i++<8) hc = (hc << 1);
fputc(hc,obj);
}
}while(c); //c=0时文件结束
}
12 *多叉树及其应用
12.1 多叉树的基本概念
每个树节点可以有两个以上的子节点,称为m阶多叉树,或称为m叉树。
12.2 多叉树的主要应用
多叉树通常用于大数据的快速检索和信息更新。本课程将在查找(searching)一讲中介绍下面多叉树的应用:
- B树
- Trie树
12.3 多叉树的遍历算法
类型定义
1
2
3
4
5
6
7#define MAXD 3 //树的度
struct node{
Datatype data;
struct node *next[MAXD];
};
typedef struct node TNode;
typedef struct node *TNodeptr;深度优先遍历算法
1
2
3
4
5
6
7
8
9void DFStree(TNodeptr t){
int i;
if(t != NULL){
VISIT(t); // 访问t指向结点
for(i=0; i<MAXD; i++)
if(t->next[i] != NULL)
DFStree(t->next[i]);
}
}广度优先遍历算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14void BFStree(TNodeptr t){
TNodeptr p;
int i;
if(t!=NULL){
enQueue(t);
while(!isEmpty()){ // 若队列不空
p= deQueue();
VISIT(p);
for(i=0; i<MAXD; i++) // 依次访问p指向的子结点
if( p->next[i] != NULL)
enQueue(p);
}
}
}
13 总结
13.1 树的构造方法总结
自顶向下构造法
结点插入法(常用):按照树结点组成规则,找到插入位置,依次插入结点。如:BST树构造、堆构造。
基本原理:查找(插入位置)-> 插入
按层构造法:通常利用一个队来依次按层构造树(参考BFS算法)。如输入数据按层组织。
自底向上构造法
- 按照树结点的组成规则依次自底向上构造,这类方法通常要用到栈或队等数据结构,如:表达式树构造(用到栈)、Huffman树构造(用到有序表或优先队列)
13.2 递归问题的非递归算法的设计
- 递归算法的优点
- 问题的数学模型或算法设计方法本身就是递归的,采用递归算法来描述它们非常自然;
- 算法的描述直观,结构清晰、简洁;算法的正确性证明比非递归算法容易。
- 递归算法的不足
- 算法的执行时间与空间开销往往比非递归算法要大,当问题规模较大时尤为明显;
- 对算法进行优化比较困难;
- 分析和跟踪算法的执行过程比较麻烦;
- 描述算法的语言不具有递归功能时,算法无法描述。
13.2.1 例:中序遍历的非递归算法
用自然语言表达的算法
- 若p指向的结点非空,则将p指的结点的地址进栈,然后,将p指向左子树的根;
- 若p指向的结点为空,则从堆栈中退出栈顶元素p,访问该结点,然后,将p指向右子树的根;
- 重复上述过程,直到p为空,并且堆栈也为空。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// STACK[0..M-1] -- 保存遍历过程中结点的地址;
// top -- 栈顶指针,初始为-1;
// p -- 为遍历过程中使用的指针变量,初始时指向根结点。
void inorder(BTNodeptr t){
BTNodeptr stack[M], p=t;
int top=-1;
if(t!=NULL)
do {
for(; p!=NULL; p=p->left)
stack[++top]=p;
p=stack[top– –];
VISIT(p);
p=p->right;
}while(!(p==NULL && top==-1));
}
13.2.2 例:已知具有n个结点的完全二叉树采用顺序存储结构,结点的数据信息依次存放于一维数组BT[0..n-1]中,写出中序遍历二叉树的非递归算法。
用自然语言表达的算法:
- 若i指向的结点非空,则将i进栈,然后,将i指向左子树的根(i = 2*i+1);
- 若i指向的结点为空,则从堆栈中退出栈顶元素i,访问该结点,然后将i指向右子树的根(i = 2*i+1);
- 重复上述过程,直到i指向的结点不存在,并且栈空。
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#define MaxSize 100
void inorder(Datatype bt[],int n){
int stack[MaxSize],i,top=-1;
i=0;
if(n>=0){
do{
while(i<n){
stack[++top]=i; // bt[i]的位置i进栈
i=i*2+1; // 找到i的左孩子的位置
}
i=STACK[top--]; // 退栈
VISIT(bt[i]); // 访问结点bt[i]
i=i*2+2; // 找到i的右孩子的位置
}while(!(i>n-1 && top==-1));
}
}
13.2.3 例:若某完全二叉树采用顺序存储结构,结点存放的次序为A,B,C,D,E,F,G,H,I,J,请给出该二叉树的后序序列。
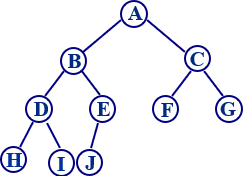
答案:HIDJEBFGCA